FCR, ACR, and AHT
By Ric Kosiba, Ph.D., Chief Data Scientist, Sharpen Technologies
I’m borrowing much of this paper from a piece I wrote for CallCentreHelper.com early this year, because I thought it would be interesting to the SWPP community.
An Age-Old Question
I was asked if I had some interesting data looking at the relationship between first call resolution and handle times. Interestingly, I had finished a presentation with some cool graphs that are enlightening.
But before we discuss the graphs, I thought I would wade into the discussion on how best to measure first contact resolution (FCR) and offer a contrarian view from common definitions. There are two basic approaches: 1) asking customers or agents whether the issue has been resolved, and 2) counting repeat calls. Most articles tend to favor the first, which seems to me to be the most straightforward. If the customer says their issue has been resolved, well then all is good, right? But there are issues with this approach:
- Sample sizes are small. Nowadays we all get bombarded with survey requests anytime we interact with any company. How often do you respond and take a survey? Small samples make poor metrics with high variability, and survey responses are typically very low.
- Self-selection bias is a problem. Who responds to these surveys? Folks with extra time and customers with a beef. These responses likely do not represent the cross-section of your overall customer base.
- Customers do not tell the truth. I lie on these surveys, based on whether I like the agent. How about you? When I do take a survey (which I do more often than I would like because of professional interest), I tend to put the best spin on my interaction if I simply feel the agent was trying. I’m not honest and I suspect many responses are similarly biased.
- The timing of the survey matters. The survey may arrive before the problem reasserts itself. If the survey comes too far after the event, I won’t even remember the interaction.
So how about the second method, measuring repeat calling? The major issue in the literature is that when customers call back for different reasons than the first, the measure becomes corrupted. The issue was resolved and now customers are onto another issue. The worry is that these unrelated callbacks may skew results. This is certainly true of many companies. For example, organizations with complex sales would never measure FCR using callbacks as a measure. Companies who specialize in business-to-business calls with high repeat traffic would likewise not use callbacks as the measure. Organizations that feature complex processes, like mortgage processing, generate legitimate and desired repeat contacts.
But for businesses that have “one and done” sorts of interactions, like your typical customer service contact center, this method makes complete sense. Here are my thoughts on it:
- Nobody calls a contact center for fun. Anybody calling a contact center back is truly befuddled, especially if there is a frustrated VRU at the beginning of any call.
- The big one: The callback version of FCR is easy to automate. Every contact can be tallied. This means we get a lot of data and near 100% metric coverage, unlike 1-10% with surveys.
- Customers who call back for different reasons than the first call are likely statistical noise. Every contact center agent will receive their similar fair share of new case callbacks in their metrics. With 100% coverage and transactional contacts, unrelated additional callbacks should be statistical nothings and just part of the callback baseline for every agent.
- Customers who call back for different reasons than the previous call may not be an aberration at all (Ha! Catch my backtrack?). Those repeat contacts represent a lost opportunity on the first call. Meaning, an agent who offers superior service may be able to surface the second issue and complete the second issue on the first call, too. I’ll show data that hints at this in a bit.
Thinking About FCR for the Agent
Right before COVID lockdowns, every Monday I traveled from my home in Maryland to Indiana, where Sharpen is located. During this time, I stayed with my parents, who are retired in Indiana. While I was there, my mom somehow gave her Amazon, cable, Apple, and other passwords to someone, who started alarm bells ringing at all these online accounts when “she” logged in from Pakistan. Her accounts were all locked. That evening, I called each of these companies to change her password. And they all went quickly, except her cable provider. There, I spoke to seven different agents and had three different chats over four hours or so, simply trying to change her password. That got me thinking. Did that company provide first contact resolution? Nope, not even close. But was there a single agent of the ten who was successful? Yes. The last agent knew the secret to change my mom’s password, and the others did not. Did the company know that they have a hard time with changing locked account passwords? Probably not.
FCR, really, is an organizational metric, a “how is my contact center performing?” metric. But there should be an agent metric that measures the agent’s personal contact resolution, which we call active contact resolution or ACR.
ACR is simple. Every time a call enters the system, we check to see whether that customer has previously called within the stated time horizon (say 1 day to 7). If they have, all previous contacts are toggled to “No” for ACR, meaning they were not successful, and that the customer’s issue was previously left unresolved. The current contact is listed as “Yes,” meaning it is positive, unless the caller calls again within the preferred time window. We tally, from the history of every agent and all their contacts, their personal ACR score, the percentage of times they handled the customer’s problem correctly. We feel so strongly about this measure, that we automatically tabulate it in our Sharpen contact center platform for every call.
A rolled-up ACR represents something stronger than surveyed FCR: it represents how often your agents, as a group, handle the customer’s problem, whether they call once, twice or 10 times during the time horizon. This works beautifully, subject to the caveats about the business types we have already discussed (we know that different types of businesses may require different metrics).
Let’s Look at Some Cool Graphs
I was chatting with Aaron Feinberg at Bankers Centricity, a very smart customer of ours. He is one of those executives who is both analytically sharp and has also solved contact center problems for many years. He posed one of the age-old questions: is AHT in conflict with FCR? He suggested plotting the two. Figure 1, below, represents something similar to Aaron’s idea. On the X-axis, we plot handle time or average handle time for repeat contacts. On the Y-axis, we plot the number of repeat contacts within a 24-hour window. This is a neat visual. I’ve greyed areas of the graph that represents expensive calls — either many repeat calls or calls with long handle times.
This sort of graph is enlightening. Certainly, we would like to listen to many of these — the points with middling handle times but many repeat calls represent something that should be very interesting to management. Either the customer is needy, the agent is undertrained, or something is very wrong in our business processes. We can only really know by listening to the string of calls.
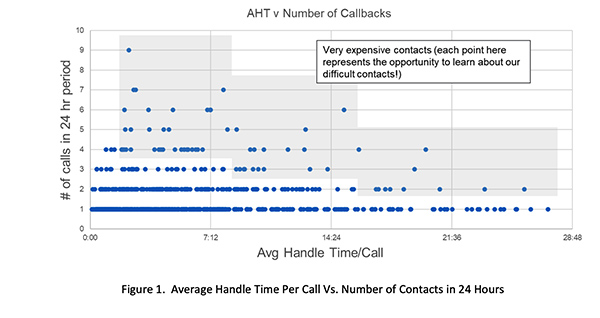
There certainly is a nice shape to this that implies longer handle times typically do not lead to as many repeat calls.
The next graph is even cooler for me — I’m proud that my daughter, an engineering intern for Sharpen, thought it up. She plotted a similar graph to Figure 1 (Figure 2) for one queue and highlighted those agents with the “worst” handle times. Would these agents also generate repeat calls?

The answer to the question is intuitive and what our experience shows: agents who spend more time with customers generate fewer repeat calls. Conscientious agents solve customer problems and may take more time to do so.
I don’t think this graph answers that old question completely, but it conforms with many a consultant’s intuition. I suspect, like in many things, the answer is somewhat in the middle. It would be nice to have low(er) handle times and great ACR. We could find examples of agents who perform this way — they are our real superstars.
One last thought on ACR. ACR measures not just how well an agent handles the current question, but also how well they manage the customer. Do they anticipate other questions? Do they probe a bit? Let’s be honest, customers don’t want to talk to us — it’s really not a treat. If an agent can spend a little time to make sure customers are completely taken care of, it is a win-win. Neither we nor the customer wants to speak to each other again.
OK. One more last thought on ACR. Our experience (we have a free performance management tool built into our contact center platform and we have a ton of data) shows that ACR correlates directly with customer satisfaction scores. When ACR improves, so does customer satisfaction. Neat!
Ric Kosiba is a charter member of SWPP and is the Chief Data Scientist at Sharpen Technologies. He can be reached at rkosiba@sharpencx.com or (410) 562-1217. Sharpen Technologies builds the Agent First contact center platform, designed from the ground up with the agent’s experience in mind. A happy agent makes happy customers!