Newsletter Table of Content

Four Reasons to Remove Forecast Accuracy from your Performance Evaluations
By Tiffany LaReau, Human Numbers
Forecast accuracy alone does not provide enough information.
There are other factors at play.
Do you evaluate your forecaster’s performance based on forecast accuracy?
The following are four reasons why you should keep it out of performance reviews.
- It is usually calculated wrong, at least in the beginning.
Consider this example where you get 15 calls against a forecast of 20. It is human nature (and I used to do it, too) to calculate forecast accuracy like this: Actual Volume divided by Forecasted Volume, or 15 ÷ 20 = 75%. This result seems right, ¾ of the forecast was right, and the math feels right in both an under- and over-forecasted situation (15 vs 20, and 20 vs 15), but it’s actually incorrect in both cases. The problem is that this result describes the distance of how far off the actual volumes were from my forecast:
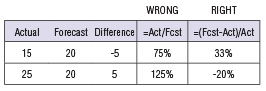
Instead, what I really need to know is how far off my forecast was from the actuals because the forecasted number is the one I’m controlling, not the actuals. The mathematically correct way to calculate this is: (Forecast – Actual) ÷ Actual. So when I’m five calls under forecast, it’s truthful to say my forecast was 33% higher than what I predicted (in other words, 33% of 15 = 5); and when I’m 5 calls over my forecast of 20, it’s truthful to say my forecast was 20% too low (5 is 20% of 25).
Incidentally, the distance in an under-forecast will always be looser, and therefore appear more favorable, than in an over-forecast, so keep that in mind when you’re setting up any benchmarking goals. Instead of using +/- 10%, it should probably be more like +13%/-8% if you want to keep those equalized up and down.
The reason this doesn’t belong in the Forecaster’s performance review is that the results of this metric do not tell you if the Forecaster used the best possible forecasting method; it’s simply a reflection that the calls performed as expected, or they did not.
- When the time comes to review forecast accuracy, most audiences are results-oriented, not process-oriented.
This an easy metric to trick, so watch out for people who try to:
- Measure it against normalized volume that excludes abandons (similar to the way some managers cheat when they report it against their service level goals). I believe it is absolutely correct to calculate this using normalized volumes that exclude excessive abandons (i.e., anything over 5%) when I need to make decisions about changing up my forecast method, but it’s highly inappropriate to do this to members outside of the WFM team without fully notating what/why it’s happening.
- Exclude blocked calls at the trunk, which hides a bigger underlying problem from the scheduling side.
- Reforecast at the last minute, too late to do anything about it, but early enough to get it in before that day’s report is published. This defeats the entire idea of having a plan in the first place but will make your stats look great. I’m not saying you can’t report this result, just be sure to include the original, too.
- Forecast Accuracy does not account for magnitude nor scale.
There is a place in Italy called the L’Aquila Fault, and they have a team of forecasters who predict earthquakes for the area. These forecasters failed to accurately predict an earthquake on the faultline, and it killed 300 people. As a result, they were fined $6.4 million in damages, and sentenced to six years in prison for manslaughter.
That is a very extreme example, and it’s absurd to compare the consequences of an earthquake against a longer wait time, yet there are still many similarities between the unpredictable, out-of-control nature of an earthquake and the profile of your common call center customer. But the point is, each call represents a single customer, regardless of how large your forecast group is.
When you report forecast accuracy as a percentage, that automatically scales the result to the single forecast group you’re using. And if you manage multiple groups of different sizes, you might have a scaling problem going on.
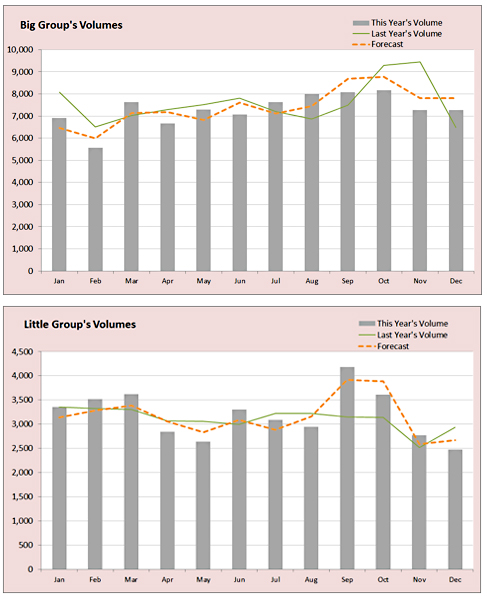
Here is an example using two groups. The big group gets 88,000 calls per year, and the smaller one gets 38,000. The solid gray bar represents the volume, which are the customers. When these charts’ axis options are left alone to auto-fit themselves, they create two pictures that make the best use of white space, but require a bit more focus to interpret that one group’s scale is 10k calls per month, and the other is 4500 calls per month.
You can put it into better perspective by simply forcing both charts to use identical axis settings, and in this case it’s completely fair to do so, because remember, the solid gray bar represents your customers, as an absolute volume, not a percentage. It’s really just a trick of the eye, and now you can easily see the difference in the magnitude of each group.
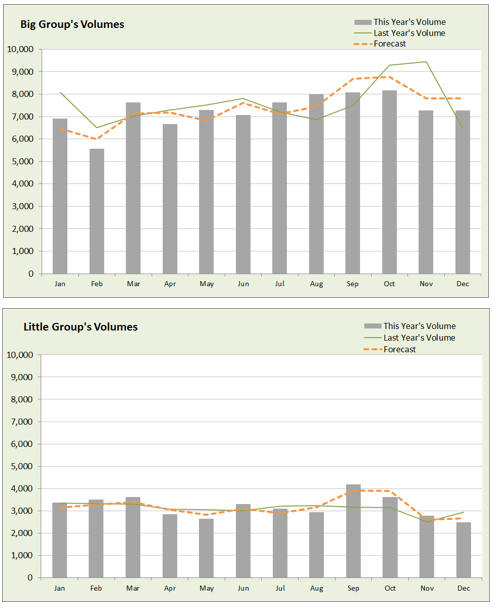
There are other factors that can affect magnitude,such as one group may have a stricter service goal and may be more “important” than the other group to upper management. Tip: You can usually tell how important a group is by seeing how willing they are to support it with the right amount of required staff and resources.
- Forecast Accuracy is only one ingredient of Forecast Ability.
Two WFM Truths: All forecasts have errors, and it’s a Forecaster’s job to be wrong.
In theory, forecasts are made up of signal plus noise. You can’t forecast for noise, because by definition, noise is random. Therefore, theoretically, when my forecast is off by the value of the portion that counts as “noise,” then my forecast is doing exactly as well as it can. It’s the relationship between the level of noise, and the size of the signal that indicates what my Forecast Potential is. And that is precisely where forecast accuracy turns into a very valuable metric for me.
I use the past 6-, 8-, or 12-weeks of forecast accuracy results percentage to tell me the MAPE, or Mean Absolute Percentage Error. The length of how far I go back depends on how stable and mature my forecast is performing. Next I subtract the MAPE from one, and that tells me my Forecast Confidence, as a value, and as a number I can share with others. So if the MAPE is 14%, my forecast confidence will be 100%-14%, and I can tell others that I am 86% confident in this forecast. It’s a great way to place value on how strongly I stand behind the forecast I’m producing, all based on the math instead of guessing. A bonus to knowing the forecast confidence is that I can also apply a range to my forecasting method, with upper and lower bound limits, which help in warding off early alerts that are unnecessary. For example, If my forecast is 5000, and my confidence is 86%, my upper limit of where I think my forecast might come in would be as high as 5,350, and as low as 4,650. Translation: I don’t want anything to pop as an alarm until it falls outside of that range of 4,650-5,350.
An added bonus here is that now I have a mathematical way to determine forecast potential of this group. I can communicate to others where I expect it to be, how strongly I feel about it, and I also now have a guiding principle for a forecast accuracy goal that is organically produced based on solid math assumptions instead of “feel-good” numbers.
But Forecast Accuracy and Forecast Confidence are still not enough to get you completely across the finish line. Both of these are super important, but using them alone does not always give you enough information to distinguish between noise and signal. Unless you have a very satisfactory, well-performing forecast at this point you may need to include one more angle: RAE, or Relative Absolute Error.
Relative Absolute Error is the measure you can use to compare the performance of multiple forecasting methods. There are a million different methods out there, and I can’t tell you which one works best, but RAE will tell you which one is working best for your specific group at any specific time. The formula is super easy: Divide the absolute forecast accuracy of the original method by the absolute forecast accuracy of the new method = ABS (Orig Fcst Acc) ÷ ABS (New Fcst Acc). If the result is 100% or greater, you have added value with the new forecast, and it’s “better.” If the result is less than 100%, the new forecast isn’t as good, and you would be degrading the value of your forecast if you switched over to it. You don’t have to limit this to just 2 methods, you can apply this to as many linear forecast models that you have running side-by-side. The one that gives you the highest RAE % score will be the winner.
This is an example of a group that tests 3 different methods every week. The original forecast was based on their member growth rate predictions, provided by marketing. In addition, I have a time-series forecast running alongside that, as well as a simple averaging method of the past few weeks of history. RAE shows me that 4 weeks ago, the simple average forecast was outperforming the original model of using member rates, but then three weeks ago, time-series finally caught up and became the forecasting leader.
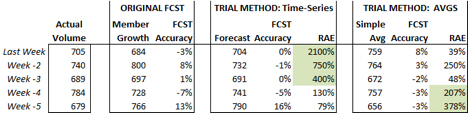
As long as those high RAE results keep showing up in the time-series method, I will continue to use it, especially for my short-term forecasts that are less than 60-days out. I know it’s unlikely that a single forecasting method will consistently last me for an entire year.
This is the kind of forecasting analysis that belongs in a performance review. Once you include the scope, the magnitude, the importance, the methodology, the judgment, the confidence level, and the forecast potential, then you can start to qualify your Forecaster.
Is it a good idea to share forecast accuracy to stakeholders? Sure, provided they contribute to the process. Bias and judgments are a huge driver of forecast accuracy, and they may not add any value. When a forecast gets tangled up in corporate politics, it’s more likely to get polluted with undesirable outcomes. Since forecast accuracy tends to produce an emotional judgment about the forecaster, I tend to keep it out of conversations that extend beyond the members of the workforce management team.
Tiffany LaReau is an independent Certified Workforce Manager at Human Numbers, a firm that provides contracted forecasting and scheduling services. She may be reached at Tiffany@HumanNumbers.com or (678) 494-1506.